А как инвертировать не весь экран, а допустим только 1 символ или одну строку?
Контроллер дисплея позволяет инвертировать изображение (целиком) аппаратно. Эта возможность и используется библиотечными функциями.
Инветрировать отдельный символ можно только программно, но в моей библиотеке такая возможность не предусмотрена. В принципе, если кому-то это нужно, можно будет сделдать в следующей версии.
Только не могу разобраться, как выводить числа. Есть printNumber для float и long, и с ними все понятно, а что делать, если нужно вывести скажем int, или unsigned long? Помогите.
При выводе int и byte они будут преобразованы в long. По поводу unsigned - уже не помню. Если есть необходимость ывводить числа именно из диапазона 2G-4G, а текущая версия это делает с минусом, создать дополнительный метод, выводящий беззнсковые путем дублирования "знакового" метода с выбрасыванием из него ветки, отвечающей за вывод отрицательных чисел.
byte ASOLED::printNumber(long long_num, byte X, byte Y){ // здесь заменить long на unsigned long
LenString = 0;
setCursorXY(X, Y);
byte char_buffer[10] = "";
byte i = 0;
byte f = 0; // number of characters
// if (long_num < 0) { // эти строчки повыбрасывать
// f++;
// printChar('-');
// long_num = -long_num;
// }
else if (long_num == 0) { // здесь удалить слово "else"
f++;
printChar('0');
printString(&NumberString[0]); //, X, Y);
return f;
}
while (long_num > 0) {
char_buffer[i++] = long_num % 10;
long_num /= 10;
}
f += i;
for(; i > 0; i--)
printChar('0'+ char_buffer[i - 1]);
printString(&NumberString[0]); //, X, Y);
return f;
}
Беззнаковый лонг я осилил. Выкинуть лишнее я могу. А вот на int компилятор ругается такими словами: call of overloaded 'printNumber(int&, int, int)' is ambiguous. Поэтому я тупо меняю тип переменных. Это просто, но как-то некошерно. А метод для int я сам осилить не могу. Как я понимаю, нужно изменить размер буфера и что-то в while loop-е, а вот, что в нем происходит, я как раз и не понимаю.
Можно, конечно, немного уменьшить размер буфера - до 6 символов, но больше ничего кроме типа немять не нужно.
В цикле while в обратном порядке (от младшего к старшему) складываются прообразы цифр - остатки от деления текущего числа на 10. Заодно само число делится на 10. И так, пока число не обратится в 0.
Скажем, у нас есть число (не как строка символов, а именно как число во внутреннем - бинарном - представлении) 1025.
На первом этапе запоминаем в 0-й элемент массива - 5, а число превращается в 102.
На втором этапе запоминаем в 1-й элемент массива - 2, а число превращается в 10.
На третьем этапе запоминаем во 2-й элемент массива - 0, а число превращается в 1.
На четвертом этапе запоминаем в 3-й элемент массива - 1, а число превращается в 0.
На пятом этапе обрануживаем, что чисто сравнялось с 0 и пора выходить из цикла.
Следующий цикл for гоним с конца массива, преобразуя числа 1, 0, 2 и 5 в символы '1', '0', '2' и '5', после чего отправляем строку на дисплей.
Здесь есть тонкость, связанная с тем, что используется кодировка с символами переменной длины, т.е. количество байт в строке не равно количеству символов: printChar() формирует нужную строку смещений символов в массиве знакогенератора, а printString() - выводит сформированную строку на дисплей.
andriano, что я делаю не так: запускаю пример Test_ASOLED_2 - все хорошо, подключаю библиотеку к своему скетчу - вместо русских символов звездочки. Нажимю в IDE "Исправить кодировку и перезагрузить", заливаю скетч - все нормально.
Если все нормально, значит, все делаете правильно. :)
Кириллица отображается на дисплее исходя из того, что кодировка в Arduino IDE - UTF8 (т.е. при стандартных настройках). В какие кодировки перекодируют используемые Вами браузер и текстовый редактор, а также какую Вы используете ОС и какие региональные настройки, я не знаю. В исходных файлах кириллица хранится как раз в UTF8. Вероятно какой-то "слишком умный" софт считает своим долгом перенастроить кодировку, как с его точки зрения правильно. Но очевидно, что после нажатия кнопки "Исправить кодировку" Arduino IDE сама перекодирует в правильный формат.
Скажите пожалуйста, как сделать, чтобы любая из функций отрисовки текста рисовала его не по строке, которую передаем в Y, а по координате в пикселях ? Как я понимаю, нужно что-то передалать в setCursorXY
Здравствуйте!
Попытался добавить в библиотеку возможность печати инвертированных символов и столкнулся с проблемой.
При задействовании инверсии вместо Русских букв печатаются звездочки.
Долгий процесс ковыряния вывел меня на функцию, которая определяет Русские буквы.
Также заметил что при задействовании инверсии уменьшается объем использованной памяти для глобальных переменных с 521 байта до 443 байт.
Я так понял что компилятор каким-то образом оптимизирует код.
Тогда взял чистую библиотеку без изменений и попробовал использовать функцию setFont() и printString() вместо printString_12x16.
Проблема повторилась. Вместо Русских букв звездочки.
Может быть подскажете что может быть не так с этой функцией?
Я так понял, что проблема в функции unsignedcharRecodeUTF_ASA(unsignedchar c) и компиляторе, который что-то не то творит с переменными. Но вот что, я не знаю. Я чайник в программировании на Arduino.
К сожалению ардуинки под рукой нету, фото с экрана прилепить не могу.
Может дело в версии IDE?
У меня 1.6.9
Еще этот эффект появляется после повторной компиляции скетча.
Т.е. я сначала загружаю в ардуину оригинальный пример, потом его изменяю и загружаю изменённый.
Смущает еще что при возникновении ошибки уменьшается использованная память под глобальные переменные. Как-будто часть шрифта не загружается или переменные оптимизируются.
Естественно если количество выводимых на экран символов одинаковое.
Попробую добраться до ардуины и сделать всё с картинками и примерами кода.
Еще попробую обновить IDE.
Она там есть, только ТС ссылки добавлять не научился, какие его годы, одолеет, мы верим в него )))
Я фигею от систем поиска - они упорно выдают в первых строчках абсолютно безграмотные статьи.
Собственно, куча воды в начале данной статьи сменяется неожиданным заявлением автора под самый конец:
Цитата:
Меня осенила здравая идея — проверить в какой кодировке работает Arduino IDE.
У любого нормального человека эта идея будет ПЕРВОЙ, как только он столкнется с проблемой русификации, а автора она осенила только под занавес.
Ну и апофеоз:
Цитата:
Выяснилось — работаем в UTF-8. Берем таблицу кодировки и получается что:
диапазону 0x80 — 0x8F соответствуют маленькие буквы от «р» до «я»
с 0x90 и до 0xAF идут заглавные по порядку «А» — «Я» исключая «Ё»
и в хвосте с 0xB0 до 0xBF маленькие от «а» до «п».
Я понимаю, что не все присутствующие способны по достоинству оценить этот перл.
Для них специально поясню: символов с кодами в диапазоне 0x80-0xFF в кодировке UTF-8 не может быть в принципе. Не использует она этот диапазон под символы.
Остается только гадать, где автор спер фото экрана с надптсью по-русски.
Я фигею от систем поиска - они упорно выдают в первых строчках абсолютно безграмотные статьи.
..............
А может это просто какие-то враги просто сбивают нас с истинного пути? Давно понял, что нельзя верить всему, что нашел в интернете.
andriano! Будь другом, помоги. Объясни как внедрить свой шрифт в мою любимую библиотеку для ili9163? Классная библиотека, работает шустро, сама по себе, без всяких дополнительных Адрафуитов, позволяет подключать внешние шрифты (не масштабируемые коряво, а любого размера). Убил много времени, но мои познания не позволили понять мне как это сделать. Может посмотришь? Библиотека имеется, могу выложить.
Причем такая картинка появляется только на втором проходе глобального цикла. На первом проходе размер шрифта нормальный, только вместо кириллицы звездочки.
Спасибо! Завтра попробую ее сравнить с тем что у меня есть. Как думаете, куда пропадают 78 байт глобальных переменных? Ведь сами строки я не меняю, только меняю функции вывода на экран и повторно компилирую скетч из библиотеки.
UPD: Сравнил. В этой версии библиотеки у Вас добавлена поддержка инвертированного текста и Вы почему-то отказались от использования функции sendData() при печати символов на экране, хотя в самой библиотеке она осталась.
И еще таки выловил условия возникновения глюка.
Если открыть пример из библиотеки, то он не будет сохраняться после изменений, но откомпилировать и загрузить в плату его можно. Видимо из-за этого что-то где-то теряется в недрах компилятора и заливается неправильная программа.
попробовал библиотеку из данной ветки, работает отлично, автору спасибо. С adafruit не мог запуститься, с этой работает, но занимаю 88% динамической памяти. Без библиоетки дисплея 65%, возможно в моем скетче и используемых библиотеках также есть что-то, от чего можно избавиться. Подскажите, а возможно ли как-то определить, что больше всего использует память. Я только учусь и вот например недавно узнал что банальный Serial.println("Hello world!"); также кушает динамическую память.
Ваша библиотека - это очень круто, легкая! Спасибо большое!
Есть несколько пожеланий:
1) сделайте пожалуйста поддержку SH1106, для экранов 1,3"
2) Могли бы вы добать еще несколько вариантов шрифтов - 24х32 18x24
1. В планах. Благо, парочка таких дисплеев есть, как только появится потребность их куда-то приспособить, так сразу займусь библиотекой.
2. А это - увольте. Шрифты - работа дизайнера, а не программиста. Если Выложите подходящие шрифты, я могу перекодировать их под данную библиотеку (в которой для экономии памяти порыдок размещения символов не повторяет следования их кодов).
Только маленбкое замечание: шрифт если шрифт 6х8 занимаетв PROGMEM около килобайта, то 18х24 будет занимать уже порядка 10 килобайт, а 32х24 - 15-20. Т.е. все вместе они в память Uno/Mini уже никак не поместятся.
PS. Я тут немножечко адаптировал библиотечку под Due, чтобы ее можно было использовать со вторым каналом I2C. Но пока сделал это некрасиво. Вместе с другими изменениями тут тоже наведу порядок. Хотя и не совсем понятно, зачем библиотека, задуманная ради экономии памяти, нужна для Due. Единственное - обнаружил, что дисплей устойчиво работает на частоте I2C 2 МГц.
PPS. Кстати, для Due мне бы хотелось иметь красивый шрифт 12х16 (а не угловатый, полученный растягиванием 6х8). Но - см.п.1.
Да не надо никаких шрифтов генерировать, все тоже самое как сейчас, только множитель на 3 и на 4. Меня, для вывода базовой инфы даже то, что сейчас, устраивает. Разве что скролла не хватает, и иногда букв побольше. Для крутых шрифтов и т.п. есть sd1306 от китайца, там даже веб-генератор есть. У вашей же библиотеки главный кайф - дешевый (по ресурсам), базовый вывод. Которого вполне хватает, в большинстве случаев.
ПС. Ваша библиотека, кстати, даже в том виде что сейчас, работает с sh1106, что экран не чистит, и мусор слева бросает. Кстати нативный размер этих 1.3" 132х64, а не 128х64. Может подправите по быстрому, раз она и так, ПОЧТИ, работает?
Т.е. нужен не новый шрифт, а только дополнительно вести коэффициенты масштабирования х3 и х4. Честно говоря, не уврен, что результат получится удовлетворительным. Уже х2 выглядит довольно угловатым. Проделать некоторую работу только для того, чтобы убедиться, что результат оказался неудовлетворительным, не хочется. Опять же, количество строк для обоих вариантов сокращается до двух, а количество символов в строке - до 7 и 5 соответственно. Если достаточно двух строк с угловатыми шрифтами, то текстовый lcd1602 вне конкуренции по всем параметрам: цене, размеру экрана, требуемым ресурсам.
По поводу sh1106, боюсь, что излишний оптимизм здесь не уместен. Кто-то из корифеев форума смотрел на него дэйташит и пришел к выводу, что контроллеры совершенно разные. Просто даже удивительно, что хоть как-то имеющийся код частично работает. Так что "поправить по-быстрому", скорее всего, не получится.
Согласен с вами, по всем пунктам.
Но так уж получилось sd1306 и sh1106 у меня есть, а вот lcd1602 нет.
То, что будет помещаться всего лишь 5 и 7 букв, плохо, но например для слова "Готово!", - 7 достаточно, а для "ОК" даже два. Но есть желание, чтобы пользователь это увидил четко, и на весь экран. К тому-же я просил скролл. И не надо больше ничего. Ещё два множителя, или хотя бы на три, и скролл - идеально.
А красивости, которые вы предлагаете, будет круто, но лучше тогда уж в виде ASOLED2. Я думаю сообщество будет радо.
Кстати, ваша библиотека отказывается выводить строки с модификатором F("Hello World!"). Это так задумано, или я как-то не так это использую. Довольно плохо, если вывода в скетче много, ОЗУ уходит.
kostyamat, некоторые из Ваших хотелок реализовал, в частности, строки из PROGMEM и поддержку SH1106. Насколько я понял, аппаратного скроллинга у 1106 нет. Ну и растягивать фонт в 3-4 раза тоже считаю нецелесообразным, он при двухкратном увеличении уже довольно угловат. Особенно на 1.3" дисплее.
Ух ты! Огромное спасибо. Б-г с ним, со скроллингом. Спасибо за 1106. А вот про растягивание, - ну зря вы так. В моем проекте не до красивостей, главное иногда внимание обратить, помигать там или шрифт резко увеличить и слово одно вывести. У многих, кто именно вашу библиотеку пользует, задачи схожы.
Если нужно красиво - пол десятка библиотек найти можно, разной степени тяжести. В вашей же главное легкость в памяти и не требовательность к ресурсам. Ища красивости, Вы неприменно придете к тяжести, и весь ваш труд затеряется, дополнив десяток.
Точно не помню, давно с ним разбирался. Кажется - есть.
Но, надеюсь Вы понимаете, что то, что уходит за один край экрана, тут же появляется с другого?
Это не 1602, у которого буфер 40 байтов, в который можно загнать строку такой же длины и скроллироваеть ее, показывая только часть в 16 символов. С графическим дисплеем такое не выйдет.
На самом деле, в Arduino всё несколько забавнее. Буквально вчера закончил работу над женитьбой вражеской библиотеки и русского шрифта.
Символы латиницы и прочие спецзнаки, заданные в строке, например,
lcd.print("ABCDh+0123*4a-=q")
прилетают однобайтовыми. в кодировке ASCII. 16 символов - 16 байт. С ними проблем не возникает от слова совсем.
Символы кириллицы... Правильно, у русских свой особенный путь, они прилетают двухбайтовыми, в кодировке UTF-8, и в строке, например,
lcd.print("БвгдёЁжз")
будет точно так же 16 байт. Но раскурив UTF-8, становится радостно, что латиница и спецсимволы повторяют ASCII, за исключением ненужных префиксов в старшем байте (0xD0 и 0xD1), которых у нас и так нет, а кириллица после откидывания, опять же, старшего байта, не пересекается с латиницей, и не нужно городить дикие таблицы преобразования (хотя и можно, если стоит задача минимизировать объём шрифтов во flash и мапить при совпадении символ кириллицы на адрес расположения аналогичного символа латиницы).
Соответственно, таблицу символов можно сделать непрерывной, начиная с 0x00 и заканчивая 0xBF. C 0x00 по 0x7F - стандартный ASCII, c 0x80 по 0xBF - кириллица с расположением символов, аналогичным UTF8. Profit? Однозначно.
И всё было бы прекрасно, если бы не Великая Русская Буква Ё и её маленькая сестричка ё. Для них не нашлось места в наших сердцах.
Можно и оставить как есть, но вдруг кому-то (например, мне) не будет давать покоя мысль, что мне нужна эта буква на моём экране? (хотя и не знаю, зачем).
И тут возникает незадача. Символ Ё имеет код 0xD081 , и если мы попытаемся в нашей свежесобранной кодировке, радостно откидывая префиксы, напечатать "Ёлочка, гори!", на экране будет "слочка, гори!", а СЛ-ки надо беречь... Да и символ ё имеет код 0xD191, и откинув префикс и напечатав "Её родители пришли", вы получите на экране совсем не то, что хотели, и, возможно, даже придётся краснеть перед теми самыми родителями. Поэтому для начала нужно определиться, как мы будем поступать с этой великой буквой.
Можно мапить её на аналогичный символ буквы Е. Но мне это показалось неспортивно. Как это так - я отправляю на экран букву "Ё", значит, я хочу получить именно "Ё", и не подсовывайте мне эти ваши "Е"! Поэтому я позволил себе вольность и отошёл от стандарта - дал в таблице шрифтов, загружаемой в контроллер, символам "Ё" и "ё" адреса 0xC0 и 0xC1 соответственно.
Ну и, собственно, код, который позволяет корректно обрабатывать кириллицу, посылаемую скетчем Arduino IDE на дисплей:
// variable to store last received symbol
private unsigned char lastSym ;
bool uc1701::write(unsigned char szMsg)
{
unsigned char j;
j = szMsg;
// skip symbol that 's unprintable in the font above
// but save its' code 'cause it can be the first part of UTF-8
if (j < 0x20 || j > 0xC1)
{
this->lastSym = j;
return 1;
}
// If there was the first half of UTF-8 symbol
// take its' second part and maybe map to a correct symbol of a codepage
//
if (lastSym == 0xD0 || lastSym == 0xD1)
{
// If it's symbol 0xD081 (Ё) or 0xD191 (ё) map them to C0 & C1
if (lastSym == 0xD0 && j == 0x81) j = 0xC0;
else if (lastSym == 0xD1 && j == 0x91) j = 0xC1;
// or just print cyrillic symbol
} /* it's not the first part of UTF-8 */
this->lastSym = j;
<далее читаем из шрифтового массива символ с нужным кодом и посылаем его на дисплей>
return 0;
}
Как то плавненько разговор сместился от конструктива к болтовне. Предлагаю вернуться к конструктиву. К сожалению сейчас совершенно нет времени заняться любимым и полезным, а потому поделюсь как делаю значки 8х5 в програмке LCD1602 v1.1
1. Сначала надо загрузить таблицу символов через File -> Load Table.
Загружаем Epson.chr. И получаем таблицу символов как на первом изображении.
2. Если мы отим отредактировать любой символ из таблицы, или нарисовать свой неповторный элемент, то щелкаем правой кнопкой мыши на любом прямоугольнике в таблице символов справа и получаем возможность редактирования данного символа через контекстное меню Edit Char.
3. Увлеченно щелкая левой кнопкой мышки по желтым квадратикам, окрашиваем их в черный цвет, а щелкая правой кнопкой мышки по черным квадратикам, возращаем им первозданную желтизну, одновременно наблюдая в окошечке Data изменение в реальном времени кода данного шедевра. Дополнительные кнопки позволяют нам очистить все, или инвертировать все. И в итоге код данного символа можно скопировать в текст программы, что очень подходит для создания небольших значков, когда они так нужны.
С уважением ко всем участникам. Пользуйтесь.
Не знаю как добавлять файлы для скачивания, а потому загрузил файл программы в архиве zip как изображение jpg. Может получится скачать. Файл называется lcd1602.zip_.jpg
...
Вывод, библиотек удобна только в случае вывода текста.
Это - не вывод, это - выдержка из аннотации к библиотеке.
Понял, спасибо.
А как инвертировать не весь экран, а допустим только 1 символ или одну строку?
---------------------------------
Отбой тревоги, разобрался.
под Attiny85 не компилируется:
А как инвертировать не весь экран, а допустим только 1 символ или одну строку?
Контроллер дисплея позволяет инвертировать изображение (целиком) аппаратно. Эта возможность и используется библиотечными функциями.
Инветрировать отдельный символ можно только программно, но в моей библиотеке такая возможность не предусмотрена. В принципе, если кому-то это нужно, можно будет сделдать в следующей версии.
Я уже это реализовал, могу выложить.
Спасибо за библиотеку. Вот то, что нужно!
Только не могу разобраться, как выводить числа. Есть printNumber для float и long, и с ними все понятно, а что делать, если нужно вывести скажем int, или unsigned long? Помогите.
При выводе int и byte они будут преобразованы в long. По поводу unsigned - уже не помню. Если есть необходимость ывводить числа именно из диапазона 2G-4G, а текущая версия это делает с минусом, создать дополнительный метод, выводящий беззнсковые путем дублирования "знакового" метода с выбрасыванием из него ветки, отвечающей за вывод отрицательных чисел.
byte ASOLED::printNumber(long long_num, byte X, byte Y){ // здесь заменить long на unsigned long LenString = 0; setCursorXY(X, Y); byte char_buffer[10] = ""; byte i = 0; byte f = 0; // number of characters // if (long_num < 0) { // эти строчки повыбрасывать // f++; // printChar('-'); // long_num = -long_num; // } else if (long_num == 0) { // здесь удалить слово "else" f++; printChar('0'); printString(&NumberString[0]); //, X, Y); return f; } while (long_num > 0) { char_buffer[i++] = long_num % 10; long_num /= 10; } f += i; for(; i > 0; i--) printChar('0'+ char_buffer[i - 1]); printString(&NumberString[0]); //, X, Y); return f; }Беззнаковый лонг я осилил. Выкинуть лишнее я могу. А вот на int компилятор ругается такими словами: call of overloaded 'printNumber(int&, int, int)' is ambiguous. Поэтому я тупо меняю тип переменных. Это просто, но как-то некошерно. А метод для int я сам осилить не могу. Как я понимаю, нужно изменить размер буфера и что-то в while loop-е, а вот, что в нем происходит, я как раз и не понимаю.
Можно, конечно, немного уменьшить размер буфера - до 6 символов, но больше ничего кроме типа немять не нужно.
В цикле while в обратном порядке (от младшего к старшему) складываются прообразы цифр - остатки от деления текущего числа на 10. Заодно само число делится на 10. И так, пока число не обратится в 0.
Скажем, у нас есть число (не как строка символов, а именно как число во внутреннем - бинарном - представлении) 1025.
На первом этапе запоминаем в 0-й элемент массива - 5, а число превращается в 102.
На втором этапе запоминаем в 1-й элемент массива - 2, а число превращается в 10.
На третьем этапе запоминаем во 2-й элемент массива - 0, а число превращается в 1.
На четвертом этапе запоминаем в 3-й элемент массива - 1, а число превращается в 0.
На пятом этапе обрануживаем, что чисто сравнялось с 0 и пора выходить из цикла.
Следующий цикл for гоним с конца массива, преобразуя числа 1, 0, 2 и 5 в символы '1', '0', '2' и '5', после чего отправляем строку на дисплей.
Здесь есть тонкость, связанная с тем, что используется кодировка с символами переменной длины, т.е. количество байт в строке не равно количеству символов: printChar() формирует нужную строку смещений символов в массиве знакогенератора, а printString() - выводит сформированную строку на дисплей.
andriano, что я делаю не так: запускаю пример Test_ASOLED_2 - все хорошо, подключаю библиотеку к своему скетчу - вместо русских символов звездочки. Нажимю в IDE "Исправить кодировку и перезагрузить", заливаю скетч - все нормально.
Если все нормально, значит, все делаете правильно. :)
Кириллица отображается на дисплее исходя из того, что кодировка в Arduino IDE - UTF8 (т.е. при стандартных настройках). В какие кодировки перекодируют используемые Вами браузер и текстовый редактор, а также какую Вы используете ОС и какие региональные настройки, я не знаю. В исходных файлах кириллица хранится как раз в UTF8. Вероятно какой-то "слишком умный" софт считает своим долгом перенастроить кодировку, как с его точки зрения правильно. Но очевидно, что после нажатия кнопки "Исправить кодировку" Arduino IDE сама перекодирует в правильный формат.
Скажите пожалуйста, как сделать, чтобы любая из функций отрисовки текста рисовала его не по строке, которую передаем в Y, а по координате в пикселях ? Как я понимаю, нужно что-то передалать в setCursorXY
MrGod, нет, нужно радикально менять принцип работы экрана. В частности, заводить экранный буфер, отжирающий значительную часть оперативной памяти.
Здравствуйте!
Попытался добавить в библиотеку возможность печати инвертированных символов и столкнулся с проблемой.
При задействовании инверсии вместо Русских букв печатаются звездочки.
Долгий процесс ковыряния вывел меня на функцию, которая определяет Русские буквы.
Также заметил что при задействовании инверсии уменьшается объем использованной памяти для глобальных переменных с 521 байта до 443 байт.
Я так понял что компилятор каким-то образом оптимизирует код.
Тогда взял чистую библиотеку без изменений и попробовал использовать функцию setFont() и printString() вместо printString_12x16.
Проблема повторилась. Вместо Русских букв звездочки.
Может быть подскажете что может быть не так с этой функцией?
NikolayD, что Вы делаете, никому не известно, но, судя по результату, делаете это Вы неправильно.
Вот ссылка на библиотеку, которую я взял из этой темы: https://github.com/NikolayDikiy/ASOLED/tree/master
Открываю пример из неё ASOLED_Demo.ino
Вместо:
LD.printString_6x8("0123456789!\"#$%&'()*+", 0, 0); LD.printString_6x8(",-./:;<=>?@[\\]^_`{|}~", 0, 1); LD.printString_6x8("ABCDEFGHIJKLMNOPQRSTU", 0, 2); LD.printString_6x8("VWXYZabcdefghijklmnop",0, 3); LD.printString_6x8("qrstuvwxyzАБВГДЕЁЖЗИЙ", 0, 4); LD.printString_6x8("КЛМНОПРСТУФХЦЧШЩЪЫЬЭЮ", 0, 5); LD.printString_6x8("Яабвгдеёжзийклмнопрст", 0, 6); LD.printString_6x8("уфхцчшщъыьэюяЇїЎў§°±µ", 0, 7);Пишу:
LD.printString("qrstuvwxyzАБВГДЕЁЖЗИЙ", 0, 1); LD.setFont(Font_12x16); LD.printString("КЛМНОПРСТУФХЦЧШЩЪЫЬЭЮ", 0, 3); LD.setFont(Font_6x8); LD.printString("Яабвгдеёжзийклмнопрст", 0, 5);На экране вместо Русских букв получаю звездочки.
Я так понял, что проблема в функции unsigned char RecodeUTF_ASA(unsigned char c) и компиляторе, который что-то не то творит с переменными. Но вот что, я не знаю. Я чайник в программировании на Arduino.
К сожалению ардуинки под рукой нету, фото с экрана прилепить не могу.
NikolayD, я не могу воспроизвести Вашу проблему:
Может дело в версии IDE?
У меня 1.6.9
Еще этот эффект появляется после повторной компиляции скетча.
Т.е. я сначала загружаю в ардуину оригинальный пример, потом его изменяю и загружаю изменённый.
Смущает еще что при возникновении ошибки уменьшается использованная память под глобальные переменные. Как-будто часть шрифта не загружается или переменные оптимизируются.
Естественно если количество выводимых на экран символов одинаковое.
Попробую добраться до ардуины и сделать всё с картинками и примерами кода.
Еще попробую обновить IDE.
Посмотрти вот эту статью по руссификации
http://robocraft.ru/blog/892.html .
Ошибка: 404
К сожалению, такой страницы не существует. Вероятно, она была удалена с сервера, либо ее здесь никогда не было.
Вернуться назад, перейти на главную
Она там есть, только ТС ссылки добавлять не научился, какие его годы, одолеет, мы верим в него )))
Она там есть, только ТС ссылки добавлять не научился, какие его годы, одолеет, мы верим в него )))
Я фигею от систем поиска - они упорно выдают в первых строчках абсолютно безграмотные статьи.
Собственно, куча воды в начале данной статьи сменяется неожиданным заявлением автора под самый конец:
Меня осенила здравая идея — проверить в какой кодировке работает Arduino IDE.
У любого нормального человека эта идея будет ПЕРВОЙ, как только он столкнется с проблемой русификации, а автора она осенила только под занавес.
Ну и апофеоз:
Выяснилось — работаем в UTF-8. Берем таблицу кодировки и получается что:
диапазону 0x80 — 0x8F соответствуют маленькие буквы от «р» до «я»
с 0x90 и до 0xAF идут заглавные по порядку «А» — «Я» исключая «Ё»
и в хвосте с 0xB0 до 0xBF маленькие от «а» до «п».
Я понимаю, что не все присутствующие способны по достоинству оценить этот перл.
Для них специально поясню: символов с кодами в диапазоне 0x80-0xFF в кодировке UTF-8 не может быть в принципе. Не использует она этот диапазон под символы.
Остается только гадать, где автор спер фото экрана с надптсью по-русски.
.............
Я фигею от систем поиска - они упорно выдают в первых строчках абсолютно безграмотные статьи.
..............
andriano! Будь другом, помоги. Объясни как внедрить свой шрифт в мою любимую библиотеку для ili9163? Классная библиотека, работает шустро, сама по себе, без всяких дополнительных Адрафуитов, позволяет подключать внешние шрифты (не масштабируемые коряво, а любого размера). Убил много времени, но мои познания не позволили понять мне как это сделать. Может посмотришь? Библиотека имеется, могу выложить.
andriano
Мои результаты изысканий:
Сначала делаю так:
LD.printString_6x8("0123456789!\"#$%&'()*+", 0, 0); LD.printString_6x8(",-./:;<=>?@[\\]^_`{|}~", 0, 1); LD.printString_6x8("ABCDEFGHIJKLMNOPQRSTU", 0, 2); LD.printString_6x8("VWXYZabcdefghijklmnop",0, 3); LD.printString_6x8("qrstuvwxyzАБВГДЕЁЖЗИЙ", 0, 4); LD.printString_6x8("КЛМНОПРСТУФХЦЧШЩЪЫЬЭЮ", 0, 5); LD.printString_6x8("Яабвгдеёжзийклмнопрст", 0, 6); LD.printString_6x8("уфхцчшщъыьэюяЇїЎў§°±µ", 0, 7); Скетч использует 9 560 байт (29%) памяти устройства. Всего доступно 32 256 байт. Глобальные переменные используют 521 байт (25%) динамической памяти, оставляя 1 527 байт для локальных переменных. Максимум: 2 048 байт.Результат: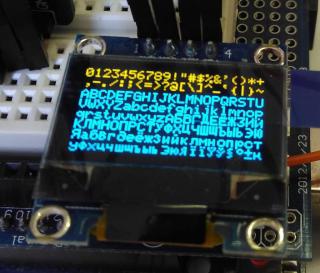
Потом меняю на такой код:
LD.printString("0123456789!\"#$%&'()*+", 0, 0); LD.printString(",-./:;<=>?@[\\]^_`{|}~", 0, 1); LD.printString("ABCDEFGHIJKLMNOPQRSTU", 0, 2); LD.printString("VWXYZabcdefghijklmnop",0, 3); LD.printString("qrstuvwxyzАБВГДЕЁЖЗИЙ", 0, 4); LD.printString("КЛМНОПРСТУФХЦЧШЩЪЫЬЭЮ", 0, 5); LD.printString("Яабвгдеёжзийклмнопрст", 0, 6); LD.printString("уфхцчшщъыьэюяЇїЎў§°±µ", 0, 7); Скетч использует 9 498 байт (29%) памяти устройства. Всего доступно 32 256 байт. Глобальные переменные используют 443 байт (21%) динамической памяти, оставляя 1 605 байт для локальных переменных. Максимум: 2 048 байт.Результат:
Причем такая картинка появляется только на втором проходе глобального цикла. На первом проходе размер шрифта нормальный, только вместо кириллицы звездочки.
Потом делаю так:
LD.setFont(Font_6x8); LD.printString("0123456789!\"#$%&'()*+", 0, 0); LD.printString(",-./:;<=>?@[\\]^_`{|}~", 0, 1); LD.printString("ABCDEFGHIJKLMNOPQRSTU", 0, 2); LD.printString("VWXYZabcdefghijklmnop",0, 3); LD.printString("qrstuvwxyzАБВГДЕЁЖЗИЙ", 0, 4); LD.printString("КЛМНОПРСТУФХЦЧШЩЪЫЬЭЮ", 0, 5); LD.printString("Яабвгдеёжзийклмнопрст", 0, 6); LD.printString("уфхцчшщъыьэюяЇїЎў§°±µ", 0, 7); Скетч использует 9 504 байт (29%) памяти устройства. Всего доступно 32 256 байт. Глобальные переменные используют 443 байт (21%) динамической памяти, оставляя 1 605 байт для локальных переменных. Максимум: 2 048 байт.Результат:
В версии IDE 1.8.1 такая-же картина.
Не могли-бы вы выложить в архиве свою библиотеку? Я так понимаю вы за последнее время её оптимизировали и этих глюков в ней не встречается.
Нет, я давно библиотекой не занимался. Но на всякий случай выкладываю: http://file.sampo.ru/3rdf4t/
Что-то антивирус ругается на эту ссылку, вот другая: https://drive.google.com/file/d/0B2sZF__Wb722NDBKTUxrQzVXUms/view?usp=sharing
Спасибо! Завтра попробую ее сравнить с тем что у меня есть. Как думаете, куда пропадают 78 байт глобальных переменных? Ведь сами строки я не меняю, только меняю функции вывода на экран и повторно компилирую скетч из библиотеки.
UPD: Сравнил. В этой версии библиотеки у Вас добавлена поддержка инвертированного текста и Вы почему-то отказались от использования функции sendData() при печати символов на экране, хотя в самой библиотеке она осталась.
И еще таки выловил условия возникновения глюка.
Если открыть пример из библиотеки, то он не будет сохраняться после изменений, но откомпилировать и загрузить в плату его можно. Видимо из-за этого что-то где-то теряется в недрах компилятора и заливается неправильная программа.
попробовал библиотеку из данной ветки, работает отлично, автору спасибо. С adafruit не мог запуститься, с этой работает, но занимаю 88% динамической памяти. Без библиоетки дисплея 65%, возможно в моем скетче и используемых библиотеках также есть что-то, от чего можно избавиться. Подскажите, а возможно ли как-то определить, что больше всего использует память. Я только учусь и вот например недавно узнал что банальный Serial.println("Hello world!"); также кушает динамическую память.
используй Serial.println(F("Hello world!"));
используй Serial.println(F("Hello world!"));
спасибо за подсказку, сократил с 65% до 56%, осталось нати еще места, которые можно оптимизировать.
я так понимаю этот вариант все что в кавычках использует как константы в EPPROM?
используй Serial.println(F("Hello world!"));
спасибо за подсказку, сократил с 65% до 56%, осталось нати еще места, которые можно оптимизировать.
я так понимаю этот вариант все что в кавычках использует как константы в EPPROM?
Нет, во флеш (в памяти для программ - PROGMEM).
Ваша библиотека - это очень круто, легкая! Спасибо большое!
Есть несколько пожеланий:
1) сделайте пожалуйста поддержку SH1106, для экранов 1,3"
2) Могли бы вы добать еще несколько вариантов шрифтов - 24х32 18x24
Ваша библиотека - это очень круто, легкая! Спасибо большое!
Есть несколько пожеланий:
1) сделайте пожалуйста поддержку SH1106, для экранов 1,3"
2) Могли бы вы добать еще несколько вариантов шрифтов - 24х32 18x24
1. В планах. Благо, парочка таких дисплеев есть, как только появится потребность их куда-то приспособить, так сразу займусь библиотекой.
2. А это - увольте. Шрифты - работа дизайнера, а не программиста. Если Выложите подходящие шрифты, я могу перекодировать их под данную библиотеку (в которой для экономии памяти порыдок размещения символов не повторяет следования их кодов).
Только маленбкое замечание: шрифт если шрифт 6х8 занимаетв PROGMEM около килобайта, то 18х24 будет занимать уже порядка 10 килобайт, а 32х24 - 15-20. Т.е. все вместе они в память Uno/Mini уже никак не поместятся.
PS. Я тут немножечко адаптировал библиотечку под Due, чтобы ее можно было использовать со вторым каналом I2C. Но пока сделал это некрасиво. Вместе с другими изменениями тут тоже наведу порядок. Хотя и не совсем понятно, зачем библиотека, задуманная ради экономии памяти, нужна для Due. Единственное - обнаружил, что дисплей устойчиво работает на частоте I2C 2 МГц.
PPS. Кстати, для Due мне бы хотелось иметь красивый шрифт 12х16 (а не угловатый, полученный растягиванием 6х8). Но - см.п.1.
Да не надо никаких шрифтов генерировать, все тоже самое как сейчас, только множитель на 3 и на 4. Меня, для вывода базовой инфы даже то, что сейчас, устраивает. Разве что скролла не хватает, и иногда букв побольше. Для крутых шрифтов и т.п. есть sd1306 от китайца, там даже веб-генератор есть. У вашей же библиотеки главный кайф - дешевый (по ресурсам), базовый вывод. Которого вполне хватает, в большинстве случаев.
ПС. Ваша библиотека, кстати, даже в том виде что сейчас, работает с sh1106, что экран не чистит, и мусор слева бросает. Кстати нативный размер этих 1.3" 132х64, а не 128х64. Может подправите по быстрому, раз она и так, ПОЧТИ, работает?
Пожалуйста!
Т.е. нужен не новый шрифт, а только дополнительно вести коэффициенты масштабирования х3 и х4. Честно говоря, не уврен, что результат получится удовлетворительным. Уже х2 выглядит довольно угловатым. Проделать некоторую работу только для того, чтобы убедиться, что результат оказался неудовлетворительным, не хочется. Опять же, количество строк для обоих вариантов сокращается до двух, а количество символов в строке - до 7 и 5 соответственно. Если достаточно двух строк с угловатыми шрифтами, то текстовый lcd1602 вне конкуренции по всем параметрам: цене, размеру экрана, требуемым ресурсам.
По поводу sh1106, боюсь, что излишний оптимизм здесь не уместен. Кто-то из корифеев форума смотрел на него дэйташит и пришел к выводу, что контроллеры совершенно разные. Просто даже удивительно, что хоть как-то имеющийся код частично работает. Так что "поправить по-быстрому", скорее всего, не получится.
Согласен с вами, по всем пунктам.
Но так уж получилось sd1306 и sh1106 у меня есть, а вот lcd1602 нет.
То, что будет помещаться всего лишь 5 и 7 букв, плохо, но например для слова "Готово!", - 7 достаточно, а для "ОК" даже два. Но есть желание, чтобы пользователь это увидил четко, и на весь экран. К тому-же я просил скролл. И не надо больше ничего. Ещё два множителя, или хотя бы на три, и скролл - идеально.
А красивости, которые вы предлагаете, будет круто, но лучше тогда уж в виде ASOLED2. Я думаю сообщество будет радо.
Кстати, ваша библиотека отказывается выводить строки с модификатором F("Hello World!"). Это так задумано, или я как-то не так это использую. Довольно плохо, если вывода в скетче много, ОЗУ уходит.
kostyamat, некоторые из Ваших хотелок реализовал, в частности, строки из PROGMEM и поддержку SH1106. Насколько я понял, аппаратного скроллинга у 1106 нет. Ну и растягивать фонт в 3-4 раза тоже считаю нецелесообразным, он при двухкратном увеличении уже довольно угловат. Особенно на 1.3" дисплее.
Теперь библиотека размещена в разделе "Проекты"
http://arduino.ru/forum/proekty/asoled-kompaktnaya-biblioteka-dlya-oled-...
Ух ты! Огромное спасибо. Б-г с ним, со скроллингом. Спасибо за 1106. А вот про растягивание, - ну зря вы так. В моем проекте не до красивостей, главное иногда внимание обратить, помигать там или шрифт резко увеличить и слово одно вывести. У многих, кто именно вашу библиотеку пользует, задачи схожы.
Если нужно красиво - пол десятка библиотек найти можно, разной степени тяжести. В вашей же главное легкость в памяти и не требовательность к ресурсам. Ища красивости, Вы неприменно придете к тяжести, и весь ваш труд затеряется, дополнив десяток.
ПС. А у 1306 аппаратного скролла случайно нет?
ПС. А у 1306 аппаратного скролла случайно нет?
Точно не помню, давно с ним разбирался. Кажется - есть.
Но, надеюсь Вы понимаете, что то, что уходит за один край экрана, тут же появляется с другого?
Это не 1602, у которого буфер 40 байтов, в который можно загнать строку такой же длины и скроллироваеть ее, показывая только часть в 16 символов. С графическим дисплеем такое не выйдет.
На самом деле, в Arduino всё несколько забавнее. Буквально вчера закончил работу над женитьбой вражеской библиотеки и русского шрифта.
Символы латиницы и прочие спецзнаки, заданные в строке, например,
lcd.print("ABCDh+0123*4a-=q")прилетают однобайтовыми. в кодировке ASCII. 16 символов - 16 байт. С ними проблем не возникает от слова совсем.
Символы кириллицы... Правильно, у русских свой особенный путь, они прилетают двухбайтовыми, в кодировке UTF-8, и в строке, например,
lcd.print("БвгдёЁжз")будет точно так же 16 байт. Но раскурив UTF-8, становится радостно, что латиница и спецсимволы повторяют ASCII, за исключением ненужных префиксов в старшем байте (0xD0 и 0xD1), которых у нас и так нет, а кириллица после откидывания, опять же, старшего байта, не пересекается с латиницей, и не нужно городить дикие таблицы преобразования (хотя и можно, если стоит задача минимизировать объём шрифтов во flash и мапить при совпадении символ кириллицы на адрес расположения аналогичного символа латиницы).
Соответственно, таблицу символов можно сделать непрерывной, начиная с 0x00 и заканчивая 0xBF. C 0x00 по 0x7F - стандартный ASCII, c 0x80 по 0xBF - кириллица с расположением символов, аналогичным UTF8. Profit? Однозначно.
И всё было бы прекрасно, если бы не Великая Русская Буква Ё и её маленькая сестричка ё. Для них не нашлось места в наших сердцах.
Можно и оставить как есть, но вдруг кому-то (например, мне) не будет давать покоя мысль, что мне нужна эта буква на моём экране? (хотя и не знаю, зачем).
И тут возникает незадача. Символ Ё имеет код 0xD081 , и если мы попытаемся в нашей свежесобранной кодировке, радостно откидывая префиксы, напечатать "Ёлочка, гори!", на экране будет "слочка, гори!", а СЛ-ки надо беречь... Да и символ ё имеет код 0xD191, и откинув префикс и напечатав "Её родители пришли", вы получите на экране совсем не то, что хотели, и, возможно, даже придётся краснеть перед теми самыми родителями. Поэтому для начала нужно определиться, как мы будем поступать с этой великой буквой.
Можно мапить её на аналогичный символ буквы Е. Но мне это показалось неспортивно. Как это так - я отправляю на экран букву "Ё", значит, я хочу получить именно "Ё", и не подсовывайте мне эти ваши "Е"! Поэтому я позволил себе вольность и отошёл от стандарта - дал в таблице шрифтов, загружаемой в контроллер, символам "Ё" и "ё" адреса 0xC0 и 0xC1 соответственно.
Ну и, собственно, код, который позволяет корректно обрабатывать кириллицу, посылаемую скетчем Arduino IDE на дисплей:
// variable to store last received symbol private unsigned char lastSym ; bool uc1701::write(unsigned char szMsg) { unsigned char j; j = szMsg; // skip symbol that 's unprintable in the font above // but save its' code 'cause it can be the first part of UTF-8 if (j < 0x20 || j > 0xC1) { this->lastSym = j; return 1; } // If there was the first half of UTF-8 symbol // take its' second part and maybe map to a correct symbol of a codepage // if (lastSym == 0xD0 || lastSym == 0xD1) { // If it's symbol 0xD081 (Ё) or 0xD191 (ё) map them to C0 & C1 if (lastSym == 0xD0 && j == 0x81) j = 0xC0; else if (lastSym == 0xD1 && j == 0x91) j = 0xC1; // or just print cyrillic symbol } /* it's not the first part of UTF-8 */ this->lastSym = j; <далее читаем из шрифтового массива символ с нужным кодом и посылаем его на дисплей> return 0; }И что это было?
PS. Кстати, все символы "прилетают" в кодировке utfr-8. Без исключения. Просто однобайтовые коды utf-8 совпадают с ASCII.
PPS. И еще: из общего порядка кроме русской Ё выпадают также целый ряд букв украинского, белорусского и македонского алфавитов.
Как то плавненько разговор сместился от конструктива к болтовне. Предлагаю вернуться к конструктиву. К сожалению сейчас совершенно нет времени заняться любимым и полезным, а потому поделюсь как делаю значки 8х5 в програмке LCD1602 v1.1
1. Сначала надо загрузить таблицу символов через File -> Load Table.
Загружаем Epson.chr. И получаем таблицу символов как на первом изображении.
2. Если мы отим отредактировать любой символ из таблицы, или нарисовать свой неповторный элемент, то щелкаем правой кнопкой мыши на любом прямоугольнике в таблице символов справа и получаем возможность редактирования данного символа через контекстное меню Edit Char.
3. Увлеченно щелкая левой кнопкой мышки по желтым квадратикам, окрашиваем их в черный цвет, а щелкая правой кнопкой мышки по черным квадратикам, возращаем им первозданную желтизну, одновременно наблюдая в окошечке Data изменение в реальном времени кода данного шедевра. Дополнительные кнопки позволяют нам очистить все, или инвертировать все. И в итоге код данного символа можно скопировать в текст программы, что очень подходит для создания небольших значков, когда они так нужны.
С уважением ко всем участникам. Пользуйтесь.
Не знаю как добавлять файлы для скачивания, а потому загрузил файл программы в архиве zip как изображение jpg. Может получится скачать. Файл называется lcd1602.zip_.jpg